Real-Time Two-Way ASL Translator on Raspberry Pi 5
Team: Liz Maria George, Naznin Amirul Haque, Ayush Kumar, Prayanshu Sharma
(M.Tech. MVLSI, ECE, IISc)
Code: GitHub Repository
1. Introduction
Communication between ASL users and non-signers is a persistent everyday barrier. This project builds a real-time, two-way ASL translator that runs entirely on a Raspberry Pi 5 — no cloud ML inference required.
Two operating modes:
| Mode | Input | Output |
|---|---|---|
| 🤟 Speaker | Pi Camera (live signs) | Spoken audio via BT speaker |
| 🎙️ Listener | Bluetooth microphone | Transcribed text on touchscreen |
The Sign-to-Speech pipeline recognises 19 ASL signs using MediaPipe landmark extraction + a CNN classifier (TFLite). Speech-to-Text uses Google Speech Recognition API.
2. System Architecture
High-Level Pipeline
┌──────────────────────────────────────────────────────────┐
│ TWO-WAY ASL TRANSLATOR │
├──────────────────────────────────────────────────────────┤
│ SIGN-TO-SPEECH (Speaker Mode) │
│ Pi Camera ─► MediaPipe Holistic ─► Features ─► CNN │
│ 640×480 Pose+Hands (75 kp) (30,504) TFLite │
│ ─► espeak-ng│
│ │
│ SPEECH-TO-TEXT (Listener Mode) │
│ BT Mic ─► PyAudio ─► SpeechRecognition ─► Display │
│ Sony XB12 Google STT API (Tkinter) │
│ │
│ SHARED: Tkinter GUI │ Threaded workers │ Mode toggle │
└──────────────────────────────────────────────────────────┘
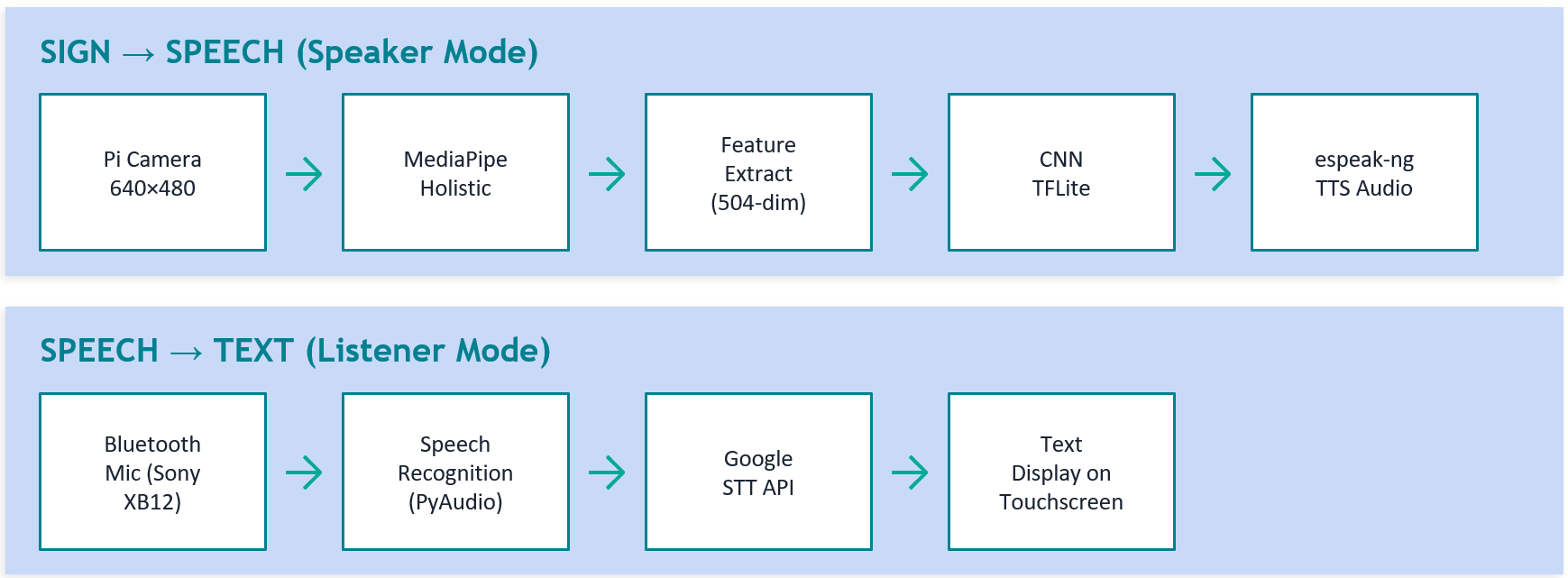
Figure 1: Top level system architecture
Sign-to-Speech: Step-by-Step
Picamera2 MediaPipe Holistic Feature Eng.
640×480 @ 30fps ──► Pose (33 kp) ──► 252-dim/frame
Left Hand (21 kp) + velocity
Right Hand (21 kp) ──► 504-dim/frame
(every 2nd frame)
──► (30, 504) tensor
↓
TFLite CNN
conf > 85%?
↓
espeak-ng TTS
Threading Architecture
Main Thread (Tkinter loop, 15 ms tick)
├── update_frame() ← camera + MediaPipe + feature buffer + render
├── InferenceWorker ← TFLite on (30,504) via maxsize-1 queue
├── TTSWorker ← espeak-ng subprocess, flushes stale requests
└── STTWorker ← PyAudio + Google STT (Listener mode only)
3. Hardware
| Component | Specification |
|---|---|
| Compute | Raspberry Pi 5 (8 GB RAM) |
| Camera | Pi Camera Module (CSI ribbon) |
| Display | Official Pi Touchscreen (DSI) |
| Audio I/O | Sony SRS-XB12 (BT speaker + mic) |
| OS | Raspberry Pi OS Bookworm 64-bit |
4. Dataset
Data collected on the Pi itself (same camera as deployment) to eliminate domain gap.
| Property | Value |
|---|---|
| Signs | 19 common ASL words |
| Clips per sign | 180 (×30 frames each) |
| Total clips | 3,420 |
| Resolution | 640×480 @ 30 FPS |
| Format | .mp4 → .npy (MediaPipe features) |
| Split | 85% train/val · 15% held-out test |
Supported signs:
| yes | no | hello | please |
| thank you | water | more | home |
| good | bad | come | go |
| stop | time | me | food |
| want | help | (18 shown) |
5. Feature Engineering
Raw landmarks → engineered features for robustness to hand size, distance, and orientation.
Per-Frame Feature Vector (252-dim)
| Feature Group | Dims | Description |
|---|---|---|
| Pose landmarks | 99 | 33 body keypoints × (x,y,z) — spatial context |
| Right hand (wrist-normalised) | 63 | 21 kp × 3, scaled by wrist-to-knuckle distance |
| Left hand (wrist-normalised) | 63 | Same normalisation |
| Right fingertip distances | 10 | C(5,2) pairwise distances (shape descriptor) |
| Left fingertip distances | 10 | Same |
| Right palm normal | 3 | Unit cross-product vector (hand orientation) |
| Left palm normal | 3 | Same |
| Inter-hand distance | 1 | Wrist-to-wrist distance (key for two-handed signs) |
+ Velocity features: np.diff of all 252 base features = 504 features/frame
Model input tensor: (30 frames × 504 features)
6. Model Training
Training on GPU workstation (train.py) — 3 automated stages:
Stage 1 — Neural Architecture Search (NAS)
Keras Tuner Hyperband searches over 1D-CNN vs LSTM, filters/units {32,64,96,128}, kernel sizes {3,5}, dropout {0.2–0.5}, LR {1e-3, 1e-4}. Up to 50 epochs per trial.
Stage 2 — 5-Fold Stratified Cross-Validation
Best NAS architecture trained for 100 epochs × 5 folds → mean val accuracy + std dev + mean best epoch (used as fixed epoch count for Stage 3).
Stage 3 — LR Scheduler Comparison
| Scheduler | Description |
|---|---|
| Constant | Fixed LR |
| Cosine Decay | Smooth anneal to zero |
| Exponential Decay | Rate 0.9 per 1/10th of steps |
| ReduceLROnPlateau | Halves LR after 5 stagnant epochs |
Best scheduler → final exported model.
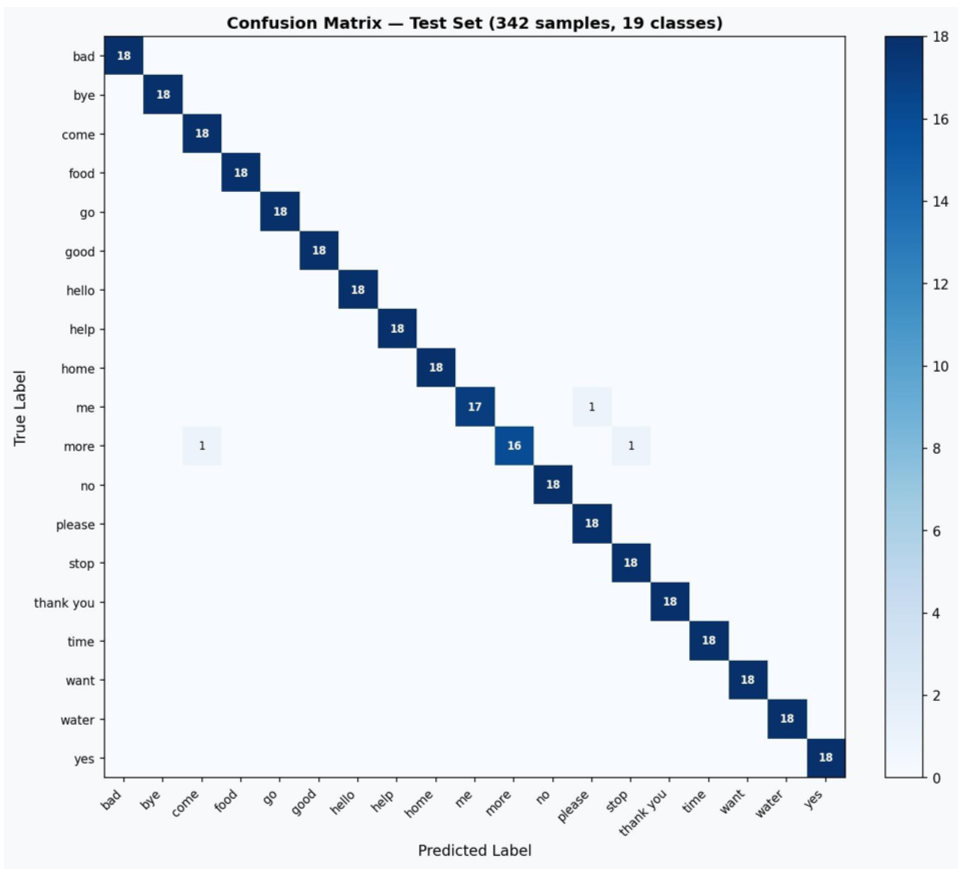
Figure 2: Confusion matrix on held-out test set (19 classes)
7. Model Optimisation & Quantisation
| Property | FP32 Model | INT8 Model |
|---|---|---|
| File size | 628 KB | 163 KB (−74%) |
| Tensor RAM | 771.9 KB | 252.5 KB (−67%) |
| x86 latency | 0.082 ms | 0.023 ms |
| Test accuracy | 99.12% | 99.12% |
- FP32: Standard TFLite conversion (
TFLITE_BUILTINS + SELECT_TF_OPS) - INT8: Post-training integer quantisation using 200 representative calibration samples; input/output remain float32 for compatibility
- Both models swappable at runtime via GUI radio buttons
8. Deployment Optimisations
| Optimisation | Effect |
|---|---|
| MediaPipe every 2nd frame + cache | ~50% CPU reduction |
| Sliding window: 30-frame, 15-frame step | Balances latency vs compute |
| Min. 8 hand-presence frames before inference | Suppresses false triggers |
Inference queue maxsize=1 |
Drops stale sequences instantly |
| TTS queue flush on new word | No audio pileup |
| 2-second same-word cooldown | Prevents repetition |
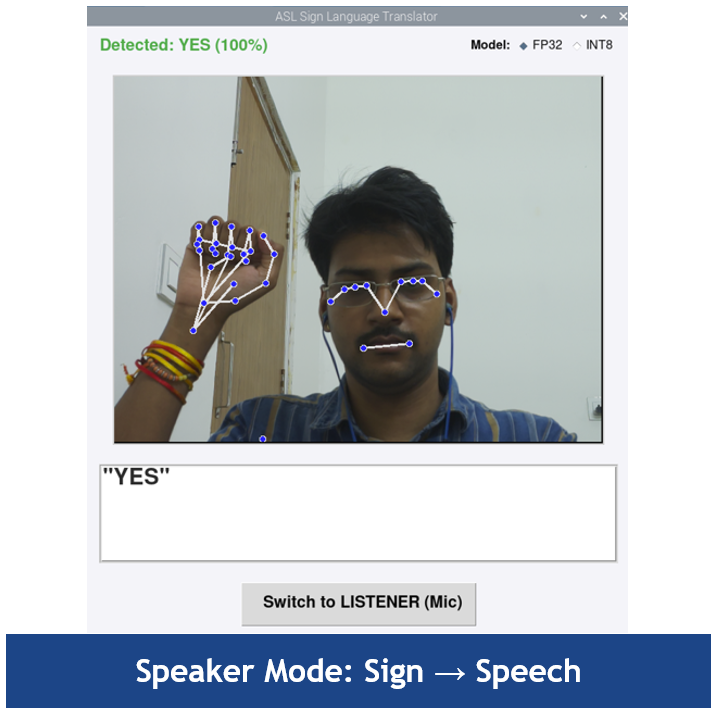
9. Application Interface
Tkinter GUI designed for touchscreen:
- Live camera feed (640×480) with MediaPipe skeleton overlay
- Transcript box — 22pt bold text for detected sign / transcribed speech
- Mode toggle — Speaker ↔ Listener
- Model selector — FP32 / INT8 radio buttons (hot-swap)
- Real-time metrics — FPS + end-to-end inference latency (ms)
- Status bar — confidence score, hand tracking state, current mode
Figure 3: GUI in Speaker mode — live skeleton overlay + detected sign
Figure 4: GUI in Listener mode — transcribed speech displayed
10. Results
| Metric | FP32 | INT8 |
|---|---|---|
| Test accuracy | 99.12% | 99.12% |
| Model size | 628 KB | 163 KB |
| x86 inference latency | 0.082 ms | 0.023 ms |
| Pi 5 end-to-end latency | ~0.5 ms | ~0.5 ms |
| GUI frame rate | 20–30 FPS | 20–30 FPS |
| No. of classes | 19 | 19 |
| Confidence threshold | 85% | 85% |
INT8 quantisation achieves 4× model compression and 3.6× faster inference with zero accuracy loss.
11. Challenges & Learnings
| Challenge | Solution |
|---|---|
| Domain gap (laptop vs Pi camera) | Collected all training data on the Pi itself |
| MediaPipe CPU cost on Pi 5 | Process every 2nd frame; reuse cached results |
| Bluetooth audio latency (~100–200 ms) | Used espeak-ng for fast local synthesis |
| Hand-size / distance variance | Wrist-normalised + hand-scale features |
| Whisper on-device STT (deferred) | Used Google Speech API; distil-whisper planned for v2 |
12. Future Work
- Vocabulary expansion: Fingerspelling (A–Z) + more conversational signs
- Fully offline STT: On-device distil-Whisper to replace Google Speech API
- Sentence construction: Sequential sign → grammatical English via lightweight LM
- Wearable form factor: Chest-/head-mounted camera on smaller SBC or custom PCB
- Continuous learning: Few-shot on-device fine-tuning for user-specific signs
13. Quick-Start Reproduction
# 1. Clone
git clone https://github.com/<your-username>/Realtime_ASL_RasPi.git && cd Realtime_ASL_RasPi
# 2. System deps (Pi OS Bookworm)
sudo apt update && sudo apt install -y \
python3-pip python3-opencv espeak-ng portaudio19-dev \
python3-tk libatlas-base-dev bluetooth bluez
# 3. Python deps
pip3 install mediapipe numpy opencv-python Pillow \
SpeechRecognition tflite-runtime picamera2
# 4. Download dataset (optional – to retrain)
python3 fetch_dataset.py
# 5. Run the translator
cd Demo_RasPi && python3 pi_two_way_translator_V2.py
See README.md for full retraining pipeline (data_capture → preprocess → train).
14. Project Structure
Realtime_ASL_RasPi/
├── Demo_RasPi/
│ ├── pi_two_way_translator_V2.py # Main app
│ ├── sign_model_fp32.tflite # 628 KB
│ └── sign_model_qat.tflite # 163 KB (INT8)
└── sign_to_speech/
├── 01_data_collection_raspi/
│ ├── data_capture_raspi_V3.py # On-device collection
│ └── preprocess.py # Feature extraction
└── 02_training/
└── train.py # NAS + K-Fold + LR search
15. References
- MediaPipe Holistic — Pose & hand landmarks (Google)
- TensorFlow Lite — On-device inference
- Keras Tuner — NAS / hyperparameter search
- espeak-ng — Open-source TTS
- SpeechRecognition — STT wrapper library
- Picamera2 — Pi camera Python API
AI Tools Disclosure: GitHub Copilot used for Tkinter boilerplate. Claude used for documentation. All architecture, feature engineering, and system design decisions were made by the team.
Team
| Name | Affiliation | Contribution | |
|---|---|---|---|
| Liz Maria George | M.Tech MVLSI, ECE, IISc | lizgeorge@iisc.ac.in | Dataset collection, feature engineering |
| Naznin Amirul Haque | M.Tech MVLSI, ECE, IISc | nazninhaque@iisc.ac.in | Dataset collection, feature engineering |
| Ayush Kumar | M.Tech MVLSI, ECE, IISc | ayush1@iisc.ac.in | Integration, GUI, data collection script |
| Prayanshu Sharma | M.Tech MVLSI, ECE, IISc | prayanshus@iisc.ac.in | Dataset collection, model development |