Offline Multimodal AI for Real-Time Banana Disease Diagnostics
[1] Ritik Kumar Badiya [2] Devendra Umbrajkar [3] Vikash Singh.
Code: GitHub Repository
Abstract
This report documents the end-to-end methodology required to port a domain-specific Large Multimodal Model (LMM) for local inference on mobile edge devices. The base architecture, MobileVLM V2 (1.4B parameters), was previously fine-tuned via Low-Rank Adaptation (LoRA) by peer researchers to specifically predict, describe, and provide remedial solutions for pathological diseases in banana plants. The primary scope of this project focuses strictly on the post-training pipeline: extracting the multimodal projector, executing variable-precision quantization (4-bit, 8-bit, 16-bit), and natively compiling the llama.cpp inference engine for edge execution. This document details the architectural dissection, hardware-specific compilation strategies (Android) and establishes a benchmarking framework to evaluate on-device throughput and latency without cloud reliance.
Acknowledgement
We would like to express our gratitude to Arun Kumar, Project Associate at the Edge Intelligence Lab (CPS), for his invaluable contribution in training the foundational vision-language model for agriculture. Our current work is built upon the robust framework and model he developed under the guidance of Prof. Pandarasamy Arjunan.
1 Introduction and Project Scope
Deploying Large Multimodal Models (LMMs) on mobile edge devices presents significant hardware challenges, primarily bounded by memory bandwidth and active RAM constraints. This project successfully establishes a pipeline to run a custom-trained multimodal model locally on an Android device, synthesizing agricultural domain specificity with edge AI optimization.
1.1 Project Scope: Banana Plant Pathology
The model utilized in this deployment pipeline is a specialized agricultural diagnostic tool. Peer researchers utilized the open-source MobileVLM V2 1.4B base model and performed LORA (Low-Rank Adaptation) fine-tuning. This fine-tuning targeted the visual recognition and linguistic description of various diseases affecting banana plants, enabling the model to not only identify visual symptoms but also generate actionable agricultural solutions. The scope of this current research phase assumes the model as a pre-trained asset. The core objective is not the training methodology, but the complex engineering task of taking these heavy, 32-bit floating-point LoRA-merged weights and successfully quantizing and deploying them onto constrained mobile hardware without destroying the model’s domain-specific reasoning capabilities.
1.2 MobileVLM V2 Architecture (Meituan-AutoML)
The repository https://github.com/Meituan-AutoML/MobileVLM defines the foundational architecture used as our base. Unlike massive desktop-grade models (e.g., LLaVA-1.5), MobileVLM V2 makes edge inference feasible through a highly optimized architectural trio:
- Text Foundation Model: A lightweight language model scaled down to 1.7B parameters.
- Vision Encoder: A pre-trained CLIP-ViT (clip-vit-large-patch14-336) model capable of extracting semantic embeddings from raw images.
- Lightweight Downsample Projector (LDPv2): The critical component for edge AI. LDPv2 effectively downsamples spatial visual tokens while preserving semantic context, drastically reducing the computational cost during the cross-modal fusion phase.
The data flow in MobileVLM V2 follows a two-stage process for output generation: During inference, the generation of the output occurs as follows:
- Vision Encoding: An input image is processed by the pre-trained CLIP ViT-L/14 vision encoder to extract high-level visual embeddings.
- Projection: These visual embeddings are passed through the Lightweight Downsample Projector (LDPv2), which compresses the number of tokens and enhances them with positional information to produce modality-aligned visual tokens.
- Language Processing and Generation: Concurrently, the input text query is tokenized. The visual tokens and the text tokens are then concatenated and fed into the foundational language model (MobileLLaMA). The final text response is generated in an autoregressive manner, predicting the next token based on both the visual and textual context.
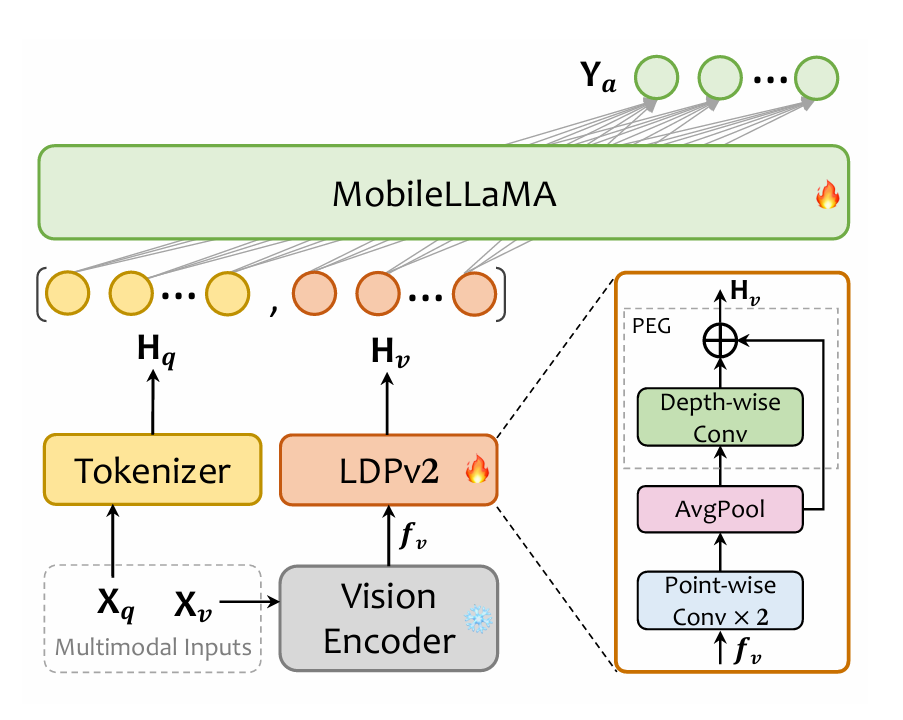 Figure 1: Model MobileVLM2 Architecture
Figure 1: Model MobileVLM2 Architecture
2 The Conversion and Surgery Pipeline
To transition the raw 32-bit floating-point fine-tuned model into a mobile-ready format, the multimodal components had to be isolated, converted, and quantized independently.
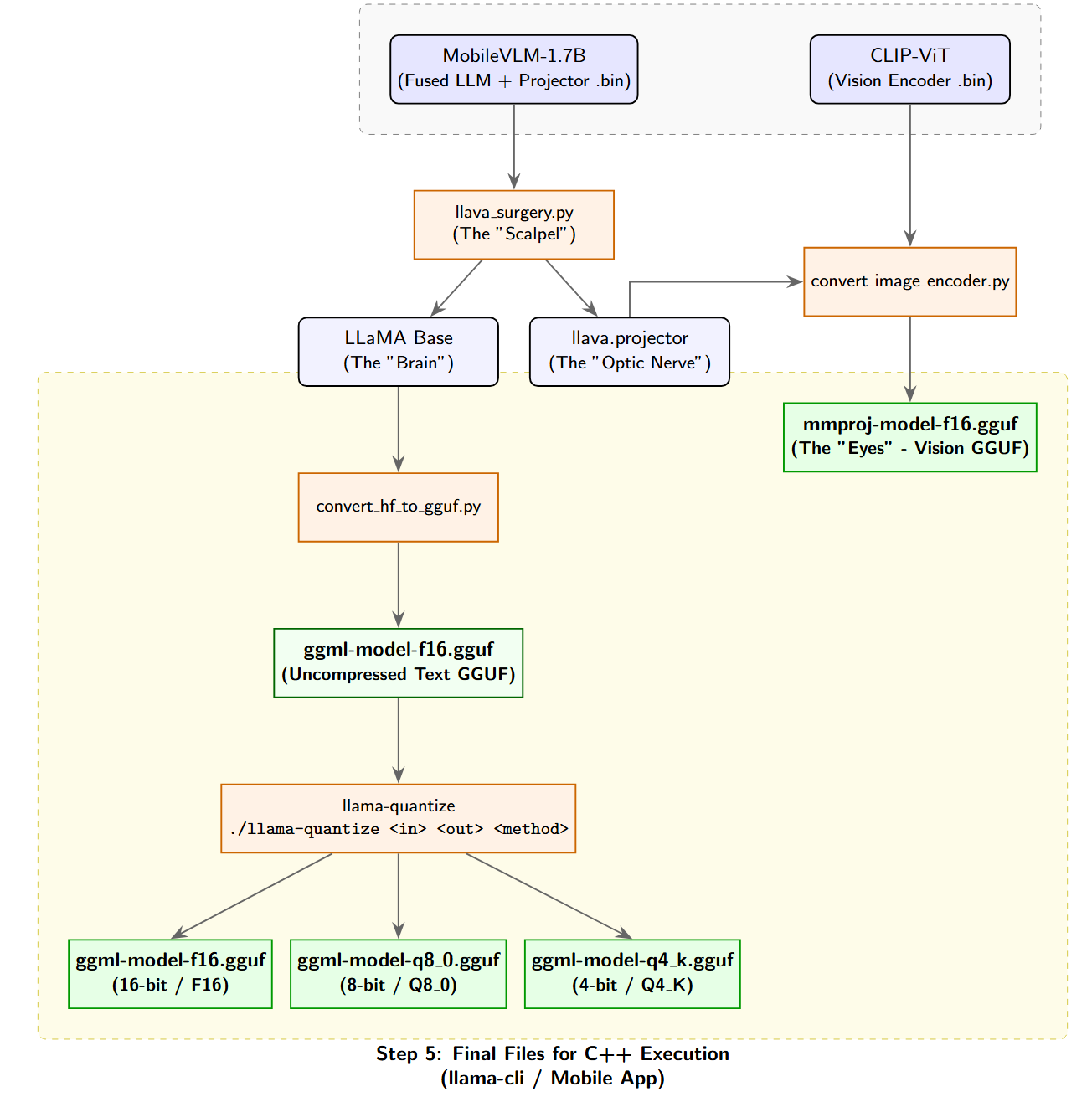
2.1 Vision Projector Extraction (The Surgery)
Because our provided model (Banana_mobilevlm_v2-1.7B) is a composite LMM, the weights linking the vision encoder to the text model must be extracted. We utilized the extraction scripts to perform ‘surgery’ on the model directory, splitting the LLaVA architecture into its text and multimodal projector constituents.
Code Execution:
python ./tools/mtmd/llava_surgery.py -m path/to/MobileVLM-1.7B
2.2 Vision Encoder Conversion and Dependency Resolution
Creating the final visual component (mmproj-model-f16.gguf) required fusing the base CLIP model with our extracted LDPv2 projector. During conversion, dependency conflicts were encountered due to PyTorch 2.6 security updates (weights_only=True) which blocked the loading of legacy .bin files. The pipeline was stabilized by forcefully pulling secure .safetensors via the Hugging Face CLI and downgrading the transformers library to version 4.45.0. Architectural Note: The vision projector is entirely independent of the text model’s quantization level. The singular mmproj-model-f16.gguf serves as the universal visual processor for all downstream text models.
Code Execution (using ldpv2 for V2 architectures):
python ./tools/mtmd/convert_image_encoder_to_gguf.py \
-m path/to/clip-vit-large-patch14-336 \
--llava-projector path/to/MobileVLM-1.7B_V2/llava.projector \
--output-dir path/to/MobileVLM-1.7B_V2 \
--projector-type ldpv2
2.3 Text Model Quantization Scaling
To evaluate the trade-off between the model’s diagnostic accuracy and computational latency, the raw 32-bit baseline (MobileLLaMA-1.4B-Base-F32.gguf) was converted to GGUF format and quantized into multiple target precisions using the llama-quantize utility. This procedure was repeated to generate q4_k_m (4-bit, ~800 MB) and F16 (16-bit, ~3.5 GB) variants, creating a comprehensive suite to benchmark edge performance.
Code Execution:
- Convert the LLaMA base model to an uncompressed GGUF (F32):
python ./examples/convert_legacy_llama.py path/to/MobileVLM-1.7B --skip-unknown - Quantize the resulting F32 model to 4-bit (q4_k):
./llama-quantize path/to/MobileVLM-1.7B/ggml-model-F32.gguf path/to/MobileVLM-1.7B/ggml-model-q4_k.gguf q4_k_s
3 Mobile Application Development and Edge Deployment
3.1 Deployment Strategy
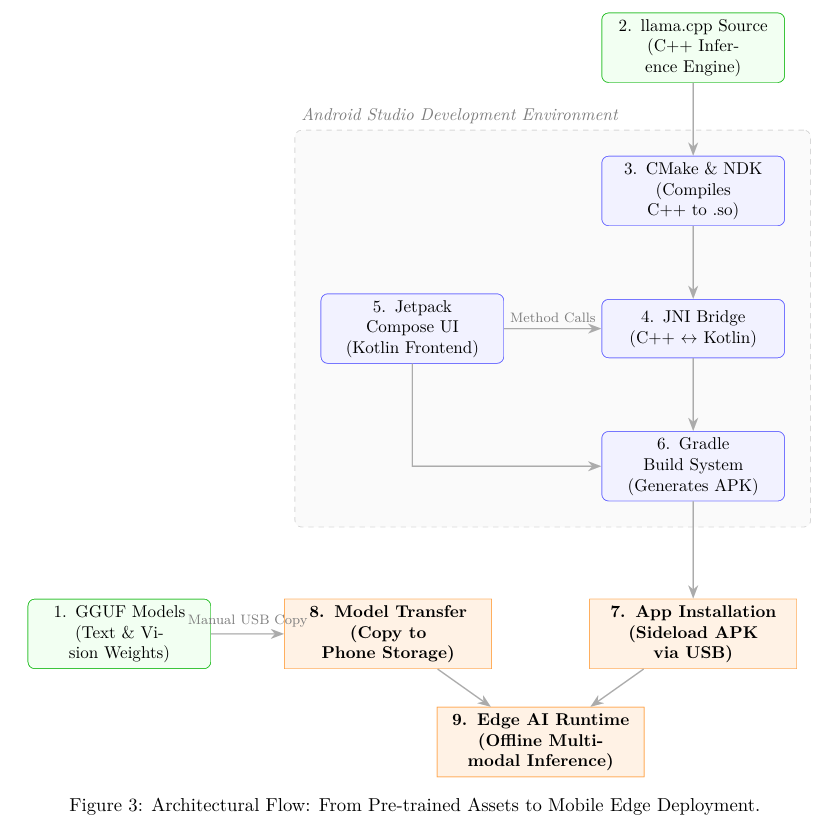
The deployment of the Vision-Language Model (VLM) for banana plant disease identification on edge devices required bridging low-level C++ inferencing engines with a native Android frontend. To achieve this, an agent-assisted development pipeline was utilized to construct a robust, asynchronous architecture. The strategy centered on leveraging the Android Native Development Kit (NDK) to cross-compile the llama.cpp library for ARM64 architectures, minimizing computational overhead and maximizing hardware utilization. Instead of relying on cloud-based APIs, the application executes fully offline by loading quantized GGUF models directly into the device’s memory, ensuring zero-latency communication, uninterrupted agricultural use, and absolute data privacy.
3.2 Development Pipeline and Architecture
The development pipeline was executed in four primary stages, focusing on memory safety, multimodal execution, and real-time hardware benchmarking.
- Native Engine Integration via CMake: The core llama.cpp and llava source files were integrated into the Android project using CMake build scripts. These scripts were configured to compile the source code into a shared native library (libllama-android.so) specifically optimized for arm64-v8a processors. Memory mapping (mmap) was explicitly enabled to efficiently handle the memory loading of large multi-gigabyte model weights.
- Multimodal JNI Bridge Construction: A Java Native Interface (JNI) was engineered to serve as the critical communication layer between the Kotlin frontend and the C++ backend. Global state pointers (llama_model, llama_context, and clip_ctx) were defined statically in the C++ layer to prevent memory loss across JNI boundaries. This bridge facilitates the simultaneous loading of the quantized text models and the vision projector, merging CLIP image embeddings with textual prompts natively.
- Asynchronous UI and State Management: To prevent Application Not Responding (ANR) fatal crashes caused by thread-blocking during intensive inference operations, token generation was fully decoupled from the main UI thread. The C++ layer streams generated tokens back to Android via a custom LlamaCallback interface. The frontend, constructed using Jetpack Compose, captures these tokens using Kotlin Flows, rendering the diagnostic output dynamically in real-time. Additionally, a scoped storage bypass was implemented to copy user-selected images into the application’s internal cache, granting the C++ backend direct POSIX file path access.
- Integrated Benchmarking Suite: A dedicated benchmarking module was embedded into the application to facilitate rigorous hardware performance analysis. Governed by independent Kotlin coroutines, this module programmatically iterates through the available model quantization levels (4-bit, 8-bit, 16-bit, and 32-bit). During inference, a secondary tracking coroutine polls the Android ActivityManager to record peak Proportional Set Size (PSS) RAM usage. Alongside Prompt Evaluation Time and Token Generation Speed (Tokens/sec), these metrics are aggregated into a unified interface, providing empirical hardware constraints for edge-deployment viability.
4 Performance Benchmarking
Deployment Hardware Specifications
The quantized MobileVLM model was deployed and evaluated on a OnePlus Pad 3. The relevant system specifications impacting inference performance are as follows:
- Device: OnePlus Pad 3
- System on Chip (SoC): Qualcomm Snapdragon 8 Elite (3 nm architecture)
- CPU: Qualcomm Oryon Octa-core, up to 4.32 GHz
- Memory (RAM): 12 GB LPDDR5X
- Storage: 512 GB UFS 4.0
- Operating System: Android 15 (OxygenOS 15)
4.1 Model Quantization and Compression Ratio
The LLama Model is quantized to 4bit, 8bit and 16bit sizes while keeping the projector quantized to 16 bit for each model as quantizing it further the Vision Encoder may lose its ability to tokenize a image.
Table 1: Model Compression Parameters and Effective Ratios
| Model Version | Size in MB | Calculation (Base / Quantized) | Effective Compression Ratio |
|---|---|---|---|
| Base | 6186.04 MB | - | 1.00x (Baseline) |
| 16-bit | 3390.52 MB | 6186.04 / 3390.52 | 1.82x |
| 8-bit | 2079.80 MB | 6186.04 / 2079.80 | 2.97x |
| 4-bit | 1429.00 MB | 6186.04 / 1429.00 | 4.33x |
4.2 Experimental Device Benchmarks: Banana Diagnostics
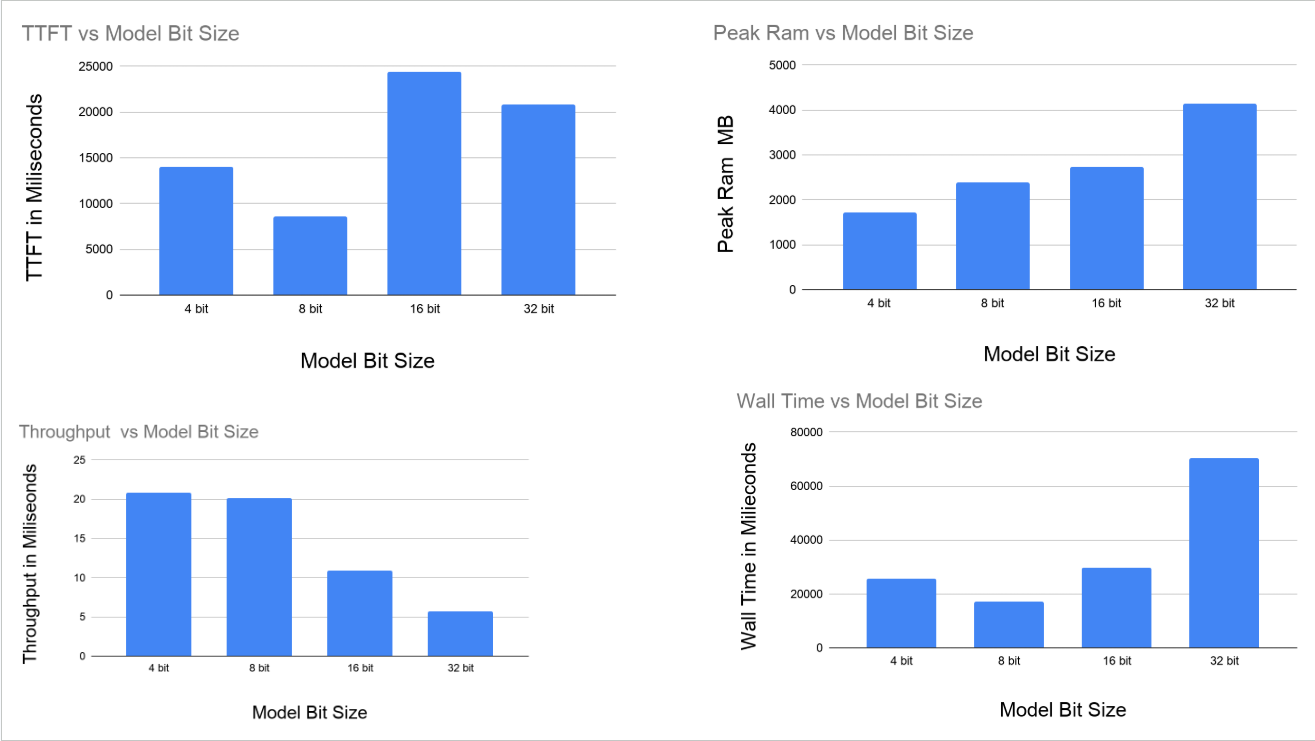
The following table serves as the primary data collection framework for on-device inference benchmarking of our domain-specific model. Metrics evaluate memory footprint, time to first token (Prompt Eval Time), and continuous generation speed across varying quantization bit-depths.
Table 2: Benchmarking for Quantized Models
| Model Bit Size | Throughput tok/s | TTFT in ms | Wall Time in ms | Peak Ram in MB |
|---|---|---|---|---|
| 4 bit | 20.79 | 14067.90 | 25583.59 | 1712.02 |
| 8 bit | 20.15 | 8626.16 | 16993.21 | 2387.79 |
| 16 bit | 10.93 | 24431.81 | 29857.66 | 2726.55 |
| 32 bit | 5.76 | 20847.32 | 70490.25 | 4135.00 |
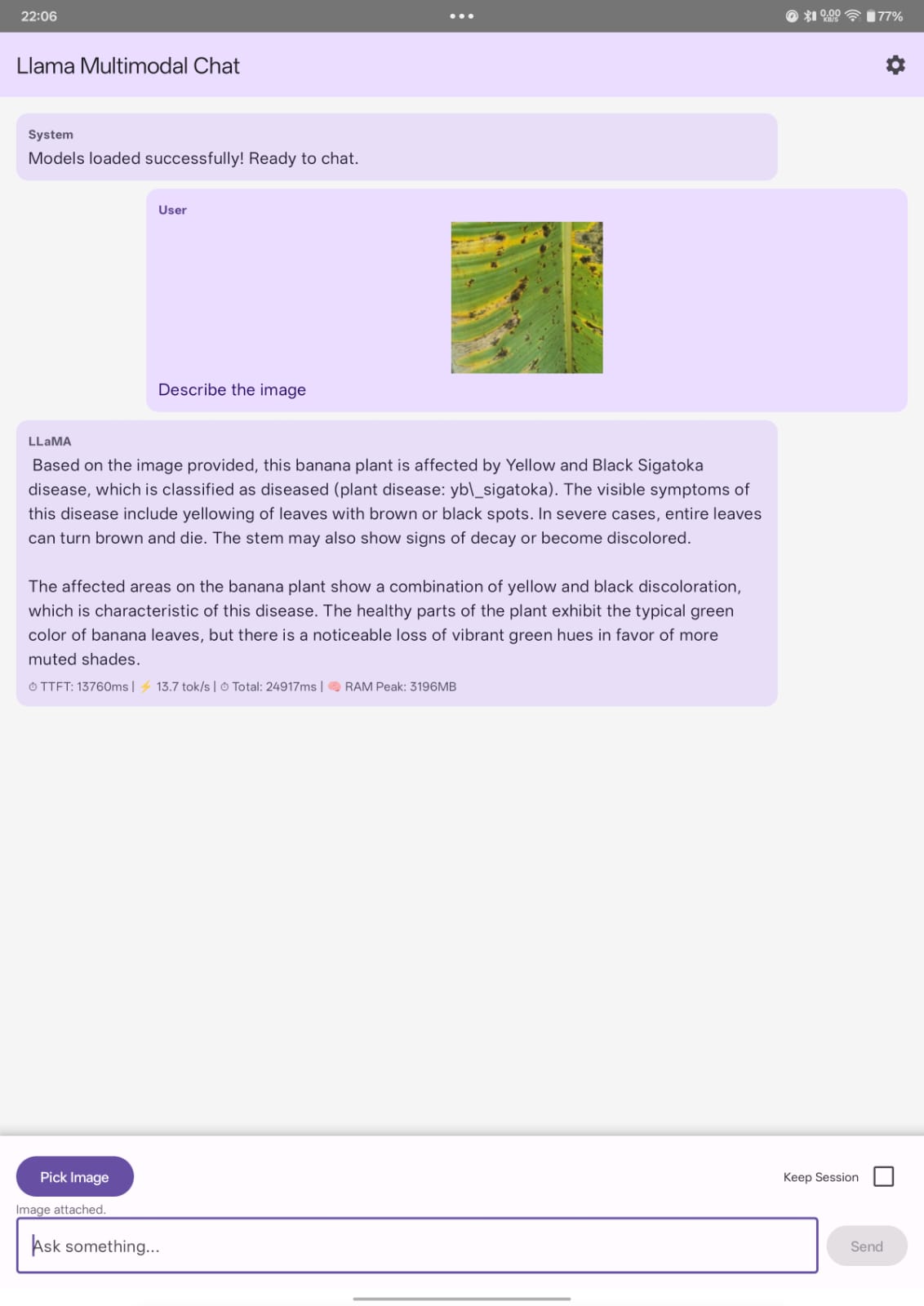
4.3 Edge Device Demo:
Here we use the app to describe the image.
5 Conclusion and Future Work
This project successfully establishes a robust, end-to-end pipeline for the edge deployment of a domain-specific Large Multimodal Model (LMM). By systematically dissecting the MobileVLM V2 architecture, extracting the Lightweight Downsample Projector (LDPv2), and employing variable-precision quantization on the language foundation, a specialized agricultural diagnostic tool for banana pathology was effectively ported to an Android ecosystem.
The deployment of the custom C++ inference engine via the Android Native Development Kit (NDK) proved that complex, multi-gigabyte models can execute entirely offline, achieving viable latency and token generation speeds on mobile hardware without cloud dependency.
To further enhance the practical utility and computational efficiency of this system in real-world agricultural settings, future iterations will focus on:
- Comprehensive Metric Evaluation: Expanding the benchmarking framework beyond pure token throughput to include rigorous diagnostic accuracy metrics, evaluating the quantized models’ real-world reliability against the baseline F32 checkpoint.
- Quantization-Aware Training (QAT): Implementing QAT during the LoRA fine-tuning phase rather than relying strictly on post-training quantization. This will help preserve the model’s domain-specific reasoning and mitigate accuracy degradation at lower bit-depths (e.g., 4-bit).
- Backend Hardware Acceleration: Transitioning the inference pipeline beyond pure CPU execution. Extending support to mobile-native backends like Vulkan or OpenCL will allow the application to leverage the device’s integrated GPU, significantly reducing latency and Time to First Token (TTFT).