Edge Clinical NLP (ClinIQ)
Code: GitHub Repository
1. Title & team
| Title | QLoRA Fine-Tuning for ASR-Robust SOAP JSON Extraction on Edge Devices |
| Author(s) | K Venu Reddy (edit; add teammates if applicable) |
| Affiliation | Indian Institute of Science (edit) |
2. Abstract
Clinicians spend substantial time on documentation; cloud NLP introduces latency, cost, and privacy concerns. We ask whether a 3B-parameter instruction model, fine-tuned with QLoRA on synthetic noisy ASR → SOAP JSON pairs, can produce schema-valid structured notes on a Raspberry Pi 5 without cloud inference. We synthesize noise using TTS → whisper.cpp on MTS-Dialog dialogues, generate gold SOAP JSON from clean dialogue via an API teacher model, train Llama-3.2-3B-Instruct, evaluate on a held-out val set (n=96), quantize to Q4_K_M GGUF, and ship a Flask application (ClinIQ) with human-in-the-loop review.
3. Problem & motivation
- Documentation burden and need for structured SOAP notes at point of care.
- Edge / privacy: local inference avoids routing clinical audio/text through third-party APIs.
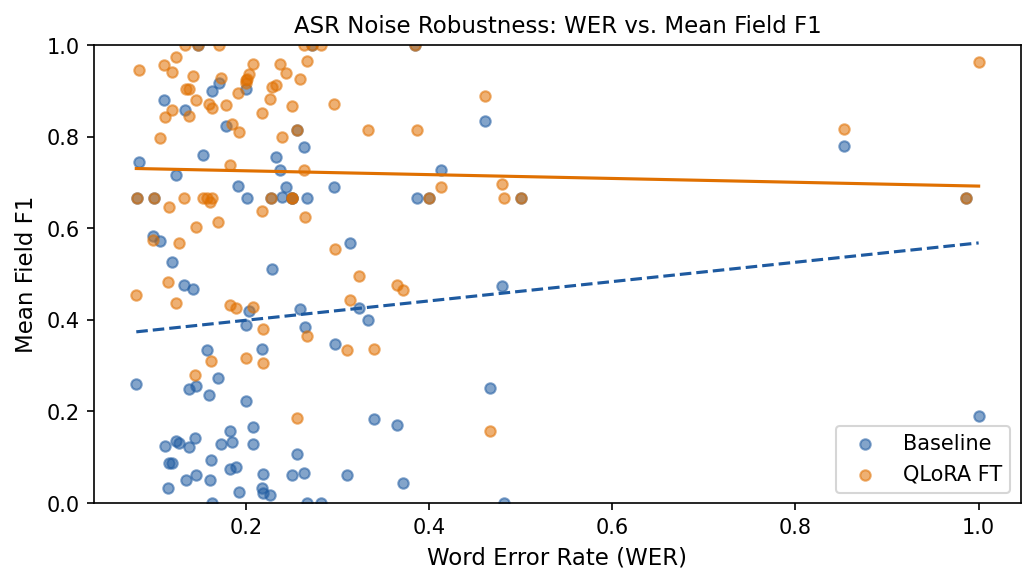
- Distribution shift: deployed systems see noisy ASR, not clean dialogue; models must map noisy transcript → valid JSON.
4. Method overview
4.1 Data pipeline (synthetic channel)
Figure 1 (recommended): Paste a diagram of: MTS-Dialog CSV → TTS → WAV → whisper.cpp → noisy_transcript parallel to clean_dialogue → DeepSeek → gold SOAP JSON.
- Source: MTS-Dialog (doctor–patient dialogues + summaries).
- Noisy transcript: synthesized audio per dialogue turn, transcribed with whisper.cpp (aligned with on-device ASR at deployment).
- Gold labels: generated from clean dialogue (not noisy text) so ASR errors do not corrupt supervision; validated with a Pydantic SOAP schema.
4.2 Fine-tuning
- Base model:
meta-llama/Llama-3.2-3B-Instruct. - Technique: QLoRA (4-bit NF4 base, LoRA on attention + MLP projections).
- Format: chat SFT — system (schema instructions), user (noisy transcript), assistant (gold JSON).
- Implementation: Hugging Face TRL
SFTTrainer,scripts/train_qlora_sft.py.
4.3 Deployment
- Merge adapters → FP16 Hugging Face checkpoint → llama.cpp
convert_hf_to_gguf.py→llama-quantize Q4_K_M(~1.87 GB vs ~6.4 GB FP16). - Inference:
llama-serverHTTP API (avoidsllama-cliinteractive chat-loop issues with Llama 3 chat templates). - ASR: whisper.cpp (
whisper-serverorwhisper-cli). - App: Flask (
app/main.py): record → transcribe → SOAP JSON → SQLite → physician review → optional FHIR export.
5. Dataset & splits
| Split | Rows (after QC) |
|---|---|
| Train | 1,172 |
| Val (held out) | 96 |
33 rows excluded due to gold JSON parse/schema failures during API generation.
External data link: MTS-Dialog repository. Processed paired JSONL and training exports are committed under data/ per course policy (if sizes prohibit git, document download scripts — see README.md).
6. Experiments & metrics
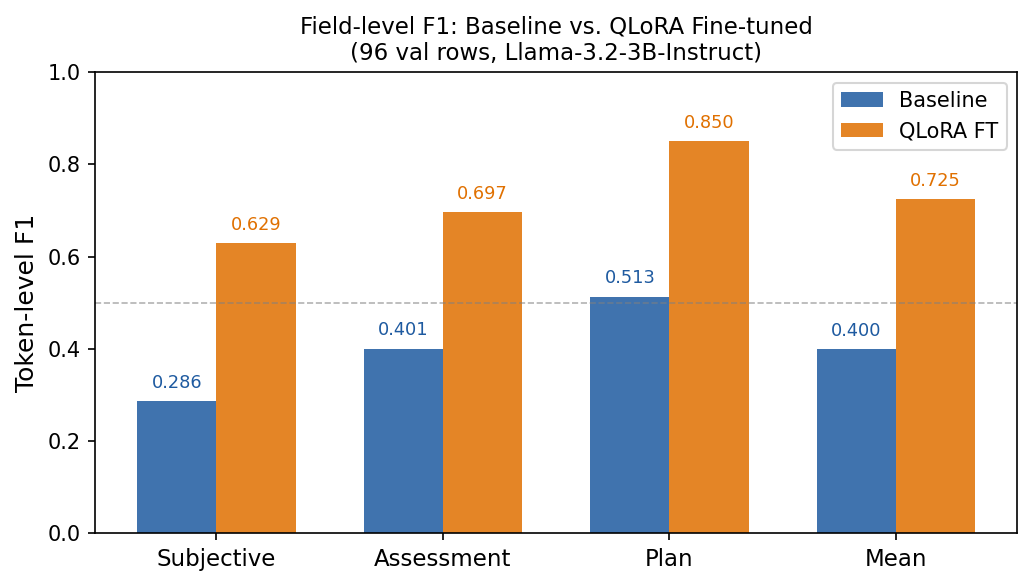
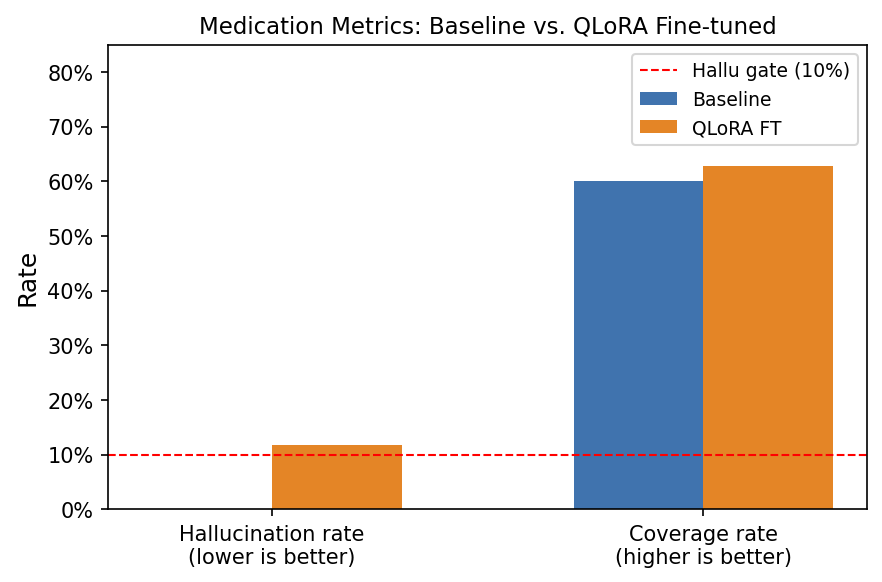
Evaluation: scripts/eval_model.py on held-out val; metrics include JSON/schema validity, token-level F1 on subjective/assessment/plan, medication coverage, and medication hallucination rate (predicted med names with no content word verbatim in noisy transcript — conservative metric).
Figure 2 (recommended): Bar chart — baseline vs 1 / 3 / 5 epochs for mean_field_f1 and med_hallucination_rate (values below).
Epoch ablation (high level)
| Model | JSON valid | Schema valid | Mean field F1 | Med hallucination rate |
|---|---|---|---|---|
| 0-shot baseline | 97.92% | 97.92% | 0.400 | 0.0% |
| 1 epoch | 100% | 100% | 0.725 | 11.8% |
| 3 epochs | 100% | 100% | 0.744 | 23.5% |
| 5 epochs (deployed default) | 100% | 100% | 0.751 | 39.4% |
Trade-off: higher epochs improve lexical F1 and med coverage; the hallucination metric rises partly because the model normalizes ASR surface forms (e.g., drug spellings) — see LLM-as-judge results in POSTER.md §10.3.
Figure 3 (optional): Screenshot of ClinIQ UI or RPi terminal showing run_app.sh + browser.
7. Engineering highlights
llama-servervsllama-cli: HTTP completion API for reliable batch-style generation on device.- Post-processing: optional medication normalizer (
src_extraction/med_normalizer.py); FHIR R4 adapter (src_extraction/fhir_adapter.py).
8. Limitations & ethics
- Not a medical device: human review required; outputs are assistive drafts.
- Metric limitations: token F1 ≠ clinical correctness; hallucination heuristic flags desirable normalizations.
- TTS diversity: two fixed voice references in the synthetic pipeline — limited speaker variability.
- English-centric default ASR; multilingual paths documented in
README.md/MASTER.md.
9. Reproducibility
| Artifact | Location |
|---|---|
| Step-by-step instructions | README.md |
| Training script | scripts/train_qlora_sft.py |
| Train → GGUF pipeline | scripts/train_quantize_nepoch.sh |
| Evaluation | scripts/eval_model.py |
| Edge / Pi setup | scripts/setup_rpi.sh, run_app.sh |
| Published weights | Hugging Face venukreddy2/llama32-3b-soap-gguf |
Secrets: Hugging Face token (Llama base model), optional DeepSeek API key for regenerating gold labels or LLM judge.
10. References (minimal)
- MTS-Dialog dataset — UCF NLP / EMNLP resources.
- Meta Llama 3.2 — model license via Hugging Face.
- Hu et al., LoRA / QLoRA line of work; llama.cpp quantization docs.
Appendix: