EdgeProbe: Investigating Binary Neural Network Acceleration on a Constrained FPGA — From Knowledge Distillation to Streaming Hardware Inference

Team: Rayan Gosh, Mehuli Chatterjee, Ayush Sagar, Tanushri Naik.
Code: GitHub Repository
1. Problem Statement, Motivation & Objectives
This project investigates how a compact image-classification pipeline can be reworked for edge deployment when compute, memory, and latency budgets are tight. Instead of keeping the full inference path in floating-point software, the project trains a binary-friendly convolutional model and maps its inference stages to an RTL accelerator built around XNOR and popcount operations. The immediate classification task is a binary hand-gesture decision: rock versus not-rock using resized grayscale images.
The motivation is to study an end-to-end edge AI flow rather than stopping at model training. A pure software CNN may be acceptable on a workstation, but edge systems often need lower latency, lower memory traffic, and tighter control over power and bandwidth. A binary CNN is a good fit for this trade-off because it collapses much of the convolution arithmetic into bitwise logic, which is more natural for FPGA-style acceleration and easier to stream from a lightweight sensor or SPI-connected device.
- Reduce convolution cost by replacing multiply-accumulate with XNOR plus popcount.
- Train a binary-friendly student model using Straight-Through Estimator and knowledge distillation.
- Export weights, thresholds, and classifier parameters into RTL-consumable
.hexand.miffiles. - Validate an end-to-end SPI-to-classification hardware pipeline in simulation.
- Compare software float inference against software binary inference to estimate efficiency gains before full FPGA deployment.
2. Proposed Solution
The system is built as a combined software-and-hardware pipeline. Public image data is preprocessed and remapped into a binary classification problem, a teacher model is trained in TensorFlow, and a compact BCNN student is trained with STE-based binary weights and binary activations. After training, the student parameters are converted into hardware-friendly artifacts for the RTL design.
The full pipeline is:
public dataset -> preprocessing -> teacher training -> BCNN student training -> binary export (.hex/.mif) -> Verilog simulation -> SPI-streamed inference -> class output
At the RTL level, the accelerator receives grayscale bytes over SPI, thresholds them into 1-bit activations, forms 3 x 3 windows with line buffers, performs two binary convolution stages, applies global pooling, and emits a final binary class decision.
3. Hardware & Software Setup
Hardware
- Target FPGA: Intel Cyclone IV
EP4CE115F29C7 - Intended input path: SPI-streamed image bytes
- Current validated source in the repository: testbench-generated SPI stream
- Planned edge camera/controller context mentioned in project notes: Arduino Nicla Vision
Software
- Python notebook workflow:
bcnn_ste_kd.ipynb - TensorFlow / Keras for teacher and student training
- TensorFlow Datasets for the dataset source
- NumPy and SciPy for export and binary reference inference
- scikit-learn for data splitting and dense-head refit
- ModelSim / ModelSim-Altera style simulation flow via
run_sim.tcl - Quartus II 13.0 as the intended synthesis flow for Cyclone IV
4. Data Collection & Dataset Preparation
The project uses the public Rock-Paper-Scissors dataset from TensorFlow Datasets and remaps it into a binary task:
- class
0: rock - class
1: not-rock, combining paper and scissors
Dataset statistics from the TensorFlow Datasets catalog:
- original dataset size:
2,892images - official split sizes:
2,520train and372test - remapped class distribution:
964rock and1,928not-rock
The notebook then shuffles the merged dataset with a fixed seed and creates a stratified 70/15/15 style split:
- training:
2,089images (696rock,1,393not-rock) - validation:
369images (123rock,246not-rock) - test:
434images (145rock,289not-rock)
Preprocessing steps:
- resize each image to
32 x 32 - convert RGB to grayscale
- normalize pixel values to
[0, 1]in software - remap labels to the binary task
- threshold pixels to 1-bit in hardware using
pixel_bin_thr = 128
5. Model Design, Training & Evaluation
The software pipeline uses a teacher-student setup. The teacher is a MobileNetV2 backbone with a lightweight classification head. The student is a small BCNN with two binary convolution layers followed by global average pooling and a dense classifier.
Student architecture from the notebook:
- BinaryConv2D:
8filters,3 x 3 - BatchNorm
- Binary activation
- BinaryConv2D:
16filters,3 x 3 - BatchNorm
- Binary activation
- GlobalAveragePooling2D
- Dense logits for
2classes
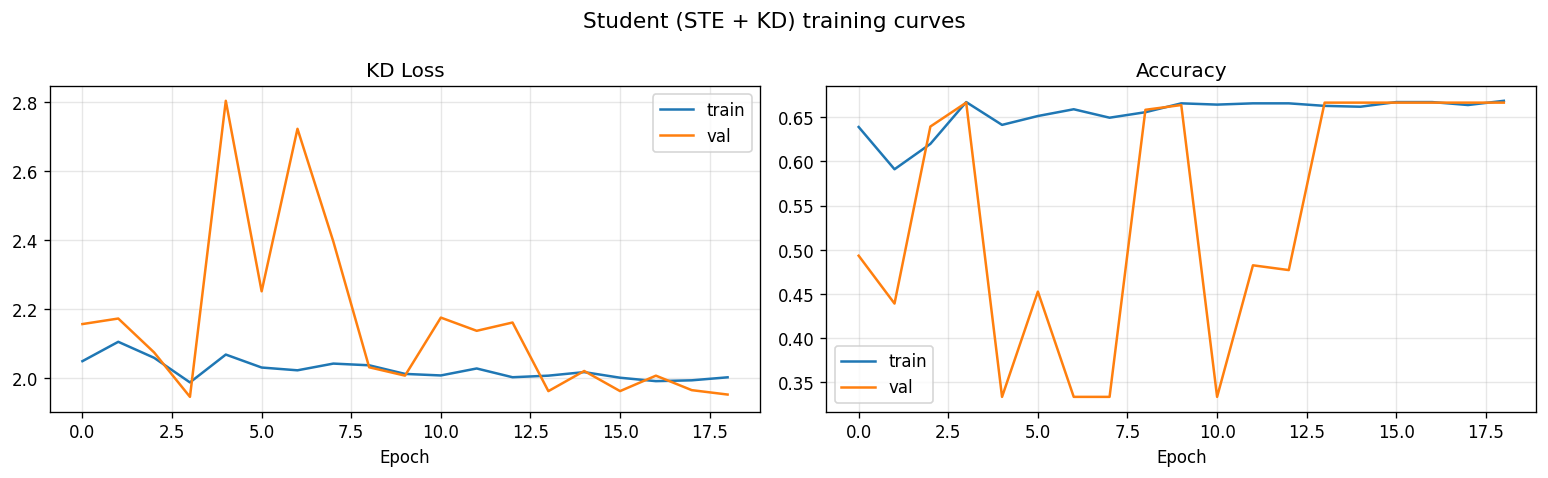
Training setup captured in the notebook:
- batch size:
64 - teacher phase 1 epochs:
20 - teacher phase 2 epochs:
10 - student maximum epochs:
60 - teacher learning rate:
1e-3, then reduced for partial unfreeze - student learning rate:
3e-4 - distillation temperature:
4.0 - distillation alpha:
0.7
Evaluation notes:
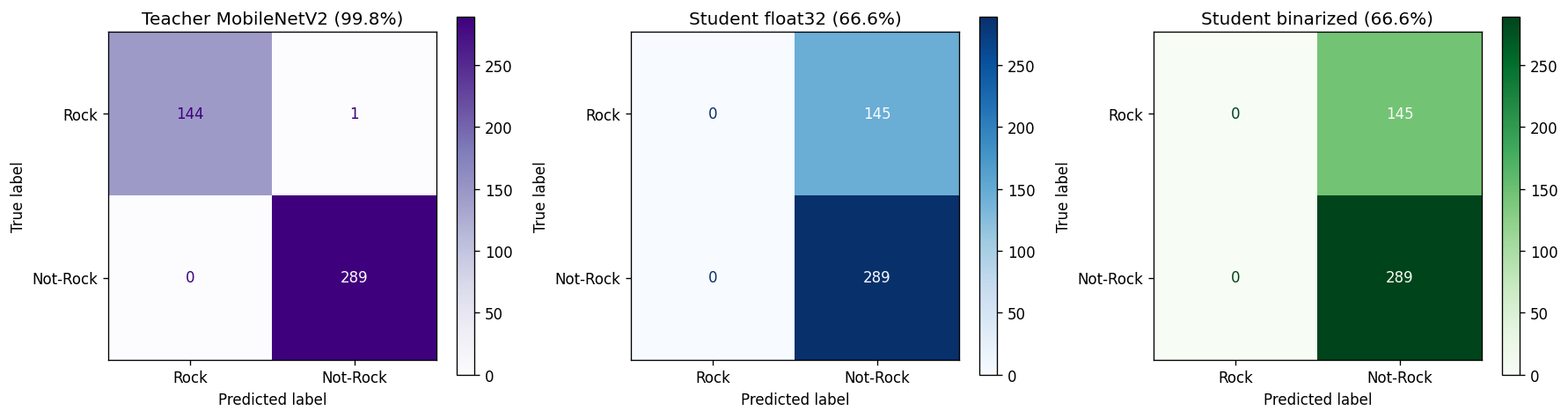
- The notebook computes teacher accuracy, student float accuracy, and final binarized-model accuracy.
- Those final accuracy values are printed by the notebook, but they are not captured in a checked-in JSON artifact in this repository snapshot.
- The repository does include a confusion-matrix figure at confusion_three_way.png, which supports the evaluation workflow, but the corresponding numeric summary is not stored separately.
{kind=link}
6. Model Compression & Efficiency Metrics
Compression and efficiency techniques used:
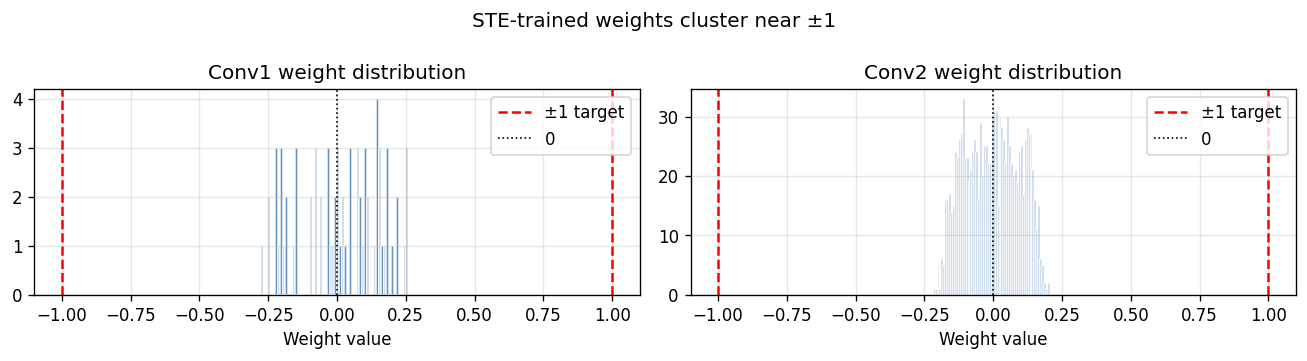
- binary weights with Straight-Through Estimator training
- binary activations in the student network
- knowledge distillation from a stronger float teacher
- post-training XNOR-style export for RTL
- fixed-point
Q8.8export for the final dense layer - XNORNet-style alpha correction and dense-head refit in the notebook
Measured artifact sizes:
- teacher model:
21,893,736bytes, about20.9 MiB - student model:
56,781bytes, about55.5 KiB - approximate storage reduction: about
385x
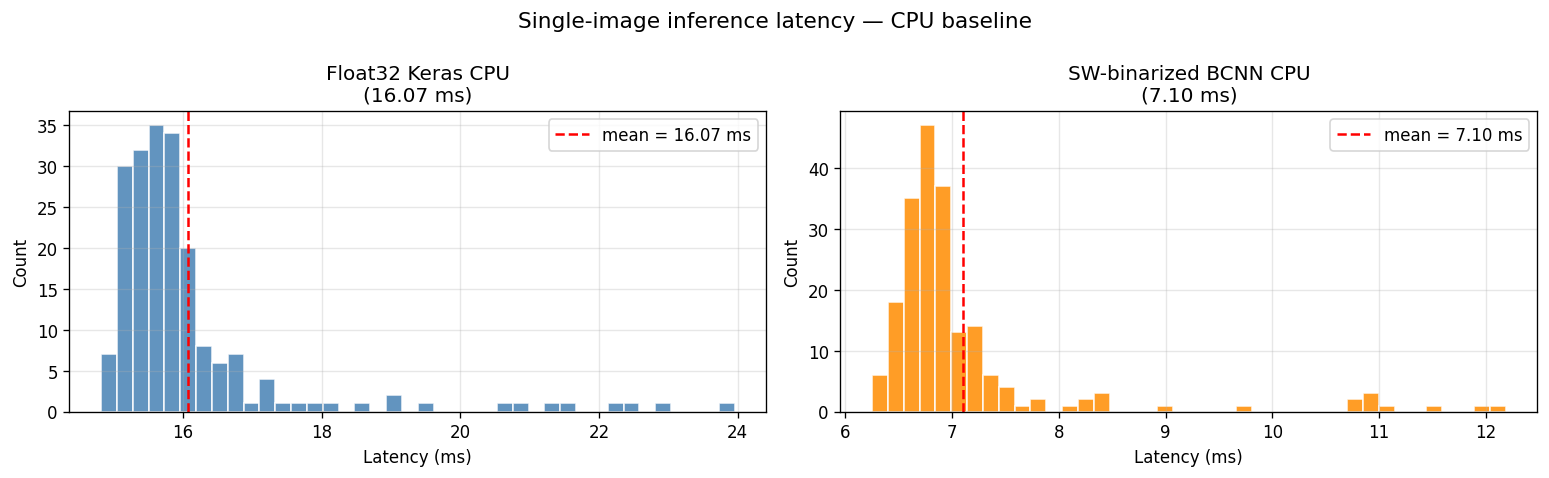
Measured timing from inference_timing.json:
- float Keras single-image inference on CPU:
16.0744 msmean,1.4302 msstd - software binary inference on CPU:
7.1023 msmean,1.0077 msstd - software speedup:
2.263x
Trade-offs observed:
- binarization reduces model size and inference cost
- binary export is more hardware-friendly than float inference
- exact final accuracy trade-off is expected, but the checked-in repository does not include the final numeric accuracy summary as a standalone artifact
- hardware resource and timing trade-offs on FPGA are not yet quantified by Quartus reports in this snapshot
7. Model Deployment & On-Device Performance
Deployment in this repository is simulation-first. The notebook exports layer parameters into .hex and .mif files, and the Verilog design consumes those files in simulation. The checked-in output bundle now includes both RTL-facing hex files and Quartus-oriented memory files.
Deployment steps used here:
- Train teacher and student in the notebook.
- Export binary layer weights, thresholds, flips, dense weights, dense bias, and test images.
- Load the exported files into the Verilog modules and testbench.
- Stream the selected test image through the simulated SPI interface.
- Observe
class_outand latency in the testbench.
Current performance status:
- simulation clocks:
50 MHzsystem clock and20 MHzSPI clock - generated golden reference file: golden_outputs.txt
- FPGA target latency in milliseconds: not yet measured in a checked-in artifact
- FPGA resource utilization, BRAM usage, and timing closure: not yet included in the repository
Because the current repository evidence is simulation-oriented, this section demonstrates deployment readiness of the exported model and RTL pipeline, but not a completed flashed-board measurement campaign.
8. System Prototype (Pictures / Figures)
Available figures in the repository:
- Dataset overview: dataset_samples.png
- Student training curves: student_training_curves.png
- Weight distribution: weight_histogram.png
- Inference timing comparison: inference_timing.png
- Evaluation figure: confusion_three_way.png
{kind=link}
{kind=link}
{kind=link}
Repository status of hardware photos:
- physical hardware setup images are not present in the current checkout
- working-board prototype photos should be added here if they are available outside the exported zip
9. Conclusions & Limitations
The project successfully demonstrates a coherent edge AI workflow from public dataset preprocessing through teacher-student training to binary export and RTL simulation. The generated artifact bundle is consistent with the documented accelerator structure, and the binary software reference shows a meaningful CPU-side speedup compared with float Keras inference.
The main limitation is that the repository currently proves the flow primarily through exported artifacts and RTL simulation, not through a fully measured FPGA deployment. Quartus synthesis results, board-level latency, power, and hardware photos are not yet included. In addition, final accuracy metrics are computed by the notebook but not preserved as machine-readable summary files in the current artifact bundle.
10. Future Work
- Add a reproducible
requirements.txtor environment file for the notebook. - Store final accuracy and classification metrics in JSON or CSV alongside the timing artifacts.
- Extend the testbench to iterate across all generated
test_img_*.hexfiles automatically. - Run Quartus synthesis and include utilization, BRAM, and timing reports.
- Validate the SPI pipeline with a real sensor or microcontroller source instead of only testbench stimulus.
- Capture true on-board latency, throughput, and power numbers.
11. Challenges & Mitigation
- Mapping a float-trained image model to a hardware-friendly binary inference path was addressed with STE-based binary training, knowledge distillation, alpha correction, and a refit dense head.
- Aligning ML export artifacts with Verilog memory-file expectations was addressed by organizing the generated bundle into
hex/,mem/, andmetadata/and preserving an RTL manifest. - Managing latency and complexity on constrained hardware was addressed by keeping the student network compact at
8and16binary filters with a32 x 32grayscale input. - Crossing from software evaluation to hardware validation was addressed with a simulation-first flow using SPI stimulus, golden outputs, and generated test images before full board deployment.
- Incomplete packaging of metrics for reporting was addressed by organizing the exported artifacts and consolidating the available measurements into this report while marking missing hardware results explicitly.
12. References
- TensorFlow Datasets, Rock-Paper-Scissors catalog: https://www.tensorflow.org/datasets/catalog/rock_paper_scissors
- Laurence Moroney, Rock-Paper-Scissors dataset homepage: http://laurencemoroney.com/rock-paper-scissors-dataset
- TensorFlow / Keras documentation: https://www.tensorflow.org/
- MobileNetV2 paper: https://arxiv.org/abs/1801.04381
- XNOR-Net paper: https://arxiv.org/abs/1603.05279
- Project notebook: bcnn_ste_kd.ipynb
- RTL design notes: RTL Design Doc.md