Compressing LLMs for Edge Devices: Using Game Theory for Pruning
Introduction
Large Language Models (LLMs) have achieved remarkable success across a variety of NLP tasks such as question answering, summarization, and text generation. However, their deployment remains a challenge due to high computational and memory demands, especially in resource-constrained environments.
To address this, our project focuses on three key objectives:
- Benchmarking the performance of multiple LLMs across standard QA datasets—SQuAD (Rajpurkar et al. [2016]), TriviaQA (Joshi et al. [2017]), and RepliQA (Monteiro et al. [2024]) under various quantization schemes (e.g., float32, int8, int4), measuring accuracy, inference time, and model size.
- Modifying Shapley value calculation to estimate the importance of individual layers using a small, representative data subset. This game-theoretic approach offers an efficient alternative to expensive search-based pruning strategies.
- Pruning models based on the modified Shapley values and deploying the resulting compressed models on edge devices. We convert pruned models into the GGUF format using the llama.cpp library and deploy them on a Raspberry Pi 4B using Ollama, enabling real-time terminal-based interaction with significantly reduced resource requirements.
This pipeline demonstrates an effective strategy for optimizing and deploying LLMs in low-power environments without major sacrifices in performance.
Large Language Models (LLMs) such as GPT, BERT, and their variants have revolutionized the field of natural language processing by achieving state-of-the-art results on a wide range of tasks. These models are typically built with hundreds of millions to billions of parameters, which allow them to capture complex linguistic patterns and generalize effectively across domains.
However, the computational and memory requirements associated with training and deploying these models pose significant challenges, particularly for real-time applications and deployment on edge devices with limited resources.
While high-performance servers with powerful GPUs can handle such models with relative ease, many practical applications—such as mobile assistants, offline chatbots, and embedded systems—require efficient deployment in constrained environments. This has led to growing interest in model compression techniques such as quantization, which reduces numerical precision, and pruning, which removes redundant or less impactful parts of the model.
Despite the effectiveness of these techniques, identifying the optimal components to prune or quantize remains a non-trivial task. Traditional methods often rely on expensive heuristics or brute-force experiments. This motivates the need for principled, efficient approaches that can guide compression without compromising performance.
In this work, we are inspired by concepts from game theory, specifically Shapley values, to develop a method that quantifies the importance of each layer in a language model. This allows us to perform targeted pruning in a resource-efficient manner. Our ultimate goal is to enable the deployment of capable LLMs on low-power edge devices without sacrificing performance on real-world tasks.
Methodology
In this work, we treat the layer pruning problem as a cooperative game. Each transformer layer in a large language model (LLM) is considered a player in a cooperative game (Ancona et al. [2020], Adamczewski et al. [2024]). The value of a coalition (subset of layers) is defined by the model’s performance (typically, loss or perplexity) when those layers are ablated.
Classical Shapley Value Definition
The Shapley value ϕᵢ of a player (layer) i represents its average marginal contribution to all possible subsets of players. It is defined as:
\[\phi_i = \sum_{S \subseteq N \setminus \{i\}} \frac{|S|! \cdot (n - |S| - 1)!}{n!} \cdot \left[ v(S \cup \{i\}) - v(S) \right]\]Where:
- N is the set of all players (layers),
- S is a subset of layers that does not include i,
- v(S) is the performance measure (e.g., loss) when subset S is ablated.
Challenge in Exact Shapley Computation
The total number of coalitions is 2ⁿ, and the number of permutations is n!, making exact Shapley computation computationally infeasible for models with more than approximately 10 layers.
To address this, we adopt a scalable approximation strategy.
Modified Shapley Value Approximation
We compute the value function v(S) as the model’s loss when a subset S of layers is masked. Instead of averaging over all permutations or all coalitions, we compute the marginal contribution of each layer by evaluating small subsets of layers (of size 1 to 4). This is based on the submodularity assumption, which states that the marginal contribution of a player decreases as the coalition grows (El Halabi et al. [2022]).
In code, this is done by computing:
\[\Delta \text{loss}(S) = \text{loss}(S) - \text{base\_loss}\]Where base_loss is the loss without any pruning.
Then, the marginal effect of layer i is estimated as:
\[\Delta_i \approx \text{mean}_{\text{overall}} \left( v(S \cup \{i\}) - v(S) \right)\]using precomputed ablation losses.
Submodularity Justification
Submodularity ensures diminishing returns: the more layers are already pruned, the less impact any new pruning has.
Formally, a function v(S) is submodular if:
\[v(S \cup \{i\}) - v(S) \geq v(T \cup \{i\}) - v(T) \quad \text{for all } S \subseteq T\]Model Deployment
To enable efficient execution of the pruned and quantized models (Gholami et al. [2021]) on edge devices, we converted the final models into the GGUF format using the llama.cpp library. This format is optimized for low-latency inference and is well-suited for deployment on resource-constrained hardware.
Hardware and Software Used
For on-device execution, we installed Ollama on a Raspberry Pi 4B, a widely used single-board computer with limited memory and processing capabilities.
The converted GGUF models were loaded and run using Ollama’s lightweight inference engine. Interaction with the models was performed via the terminal, allowing us to test and validate their functionality directly on the device.
This setup demonstrates the practical applicability of our compression and pruning pipeline for real-world, low-power NLP use cases.
Challenges and Workarounds
One challenge we faced was the inadequacy of the WikiText dataset for benchmarking (Joshi et al. [2017], Monteiro et al. [2024]). It produced inconsistent perplexity scores, included multiple languages, and lacked a prompt-response structure, making it unsuitable for evaluating text generation quality.
Workaround: We switched to well-structured QA datasets—SQuAD, TriviaQA, and RepliQA—which offer reference answers and clearer evaluation metrics (Rajpurkar et al. [2016]).
Another constraint was the limited computational resources available to run full-scale LLMs.
Workaround: We used smaller or distilled versions of models, which retain essential behaviors while significantly reducing computational cost.
Results
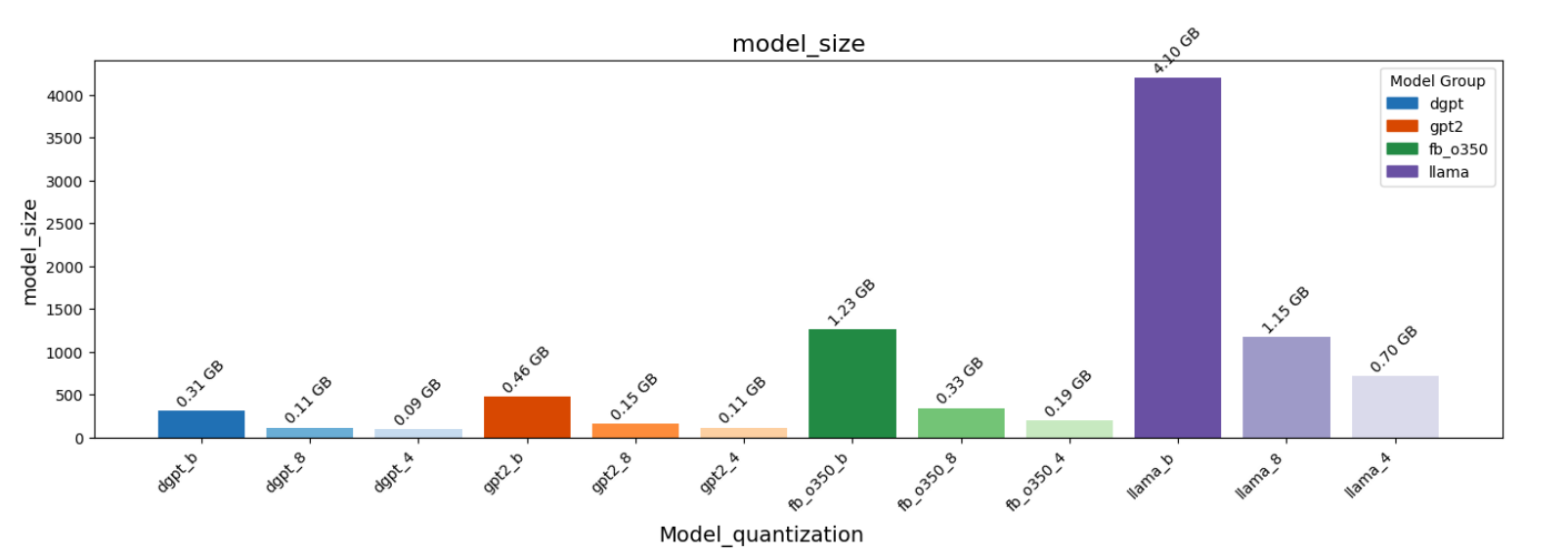
The following figures present the results obtained from our experiments on the SQuAD dataset.
For results on other datasets, please refer to our GitHub repository: https://github.com/srivnaman/EdgeAI-Project
- Figure 2: Quantization vs Model Size
- Figure 3: Quantization vs Generation Time
- Figure 4: Quantization vs BLEU Score
- Figure 5: Quantization vs Perplexity
Table 1: Loss, Perplexity, and Inference Time for Different Models under Various Pruning Strategies
| Model | Pruning Method | Loss | Perplexity | Inference Time (s) |
|---|---|---|---|---|
| GPT-2 | Before Pruning | 3.9919 | 54.16 | 1.7885 |
| Shapley Pruning | 5.1203 | 167.38 | 0.0558 | |
| Random Pruning | 4.3423 | 76.88 | 0.1823 | |
| Tiny-llama | Before Pruning | 3.2813 | 26.61 | 0.2460 |
| Shapley Pruning | 12.3030 | 220345.88 | 0.1604 | |
| Random Pruning | 3.2493 | 25.77 | 0.2601 | |
| Distil GPT2 | Before Pruning | 3.9919 | 54.16 | 0.1660 |
| Shapley Pruning | 4.0506 | 57.43 | 0.0156 | |
| Random Pruning | 4.5361 | 93.33 | 0.1150 |
Conclusion
Our pruning approach based on approximated Shapley values demonstrates a significant reduction in inference time across all evaluated models, consistently outperforming random pruning of the same number of layers.
This highlights the potential of our method for efficient deployment of LLMs. Additionally, we observe that the increase in perplexity is minimal for smaller models, while larger models exhibit a more pronounced degradation in performance. This discrepancy warrants further investigation into the interaction between model scale and pruning sensitivity.
References
- Pranav Rajpurkar, Jian Zhang, Konstantin Lopyrev, and Percy Liang. SQuAD: 100,000+ questions for machine comprehension of text. arXiv preprint arXiv:1606.05250, 2016.
- Mandar Joshi, Eunsol Choi, Daniel S Weld, and Luke Zettlemoyer. TriviaQA: A large scale distantly supervised challenge dataset for reading comprehension. arXiv preprint arXiv:1705.03551, 2017.
- Joao Monteiro et al. RepliQA: A question-answering dataset for benchmarking LLMs on unseen reference content. NeurIPS, 2024.
- Marco Ancona, Cengiz Öztireli, and Markus Gross. Shapley values as a principled metric for structured network pruning. arXiv:2006.01795, 2020.
- Kamil Adamczewski, Yawei Li, and Luc van Gool. Shapley pruning for neural network compression. arXiv:2407.15875, 2024.
- Marwa El Halabi et al. Data-efficient structured pruning via submodular optimization. NeurIPS, 2022.
- Amir Gholami et al. A survey of quantization methods for efficient neural network inference. arXiv:2103.13630, 2021.