AI-Powered Machine Learning Pipeline for Smart Manufacturing
Introduction
AutoML (Automated Machine Learning) is an emerging field that aims to automate the process of building machine learning models. AutoML emerged to increase productivity and efficiency by automating as much as possible the inefficient work that occurs while repeating this process whenever machine learning is applied [1]. Thus, it helps in increasing the use cases in which machine learning can be applied, especially in smart manufacturing where the gap in knowledge level of Artificial Intelligence (AI) in subject experts is very high.
Machine learning is critical to Industry 4.0 and 5.0. One of the main challenges in implementing machine learning in edge devices on the factory floor is the knowledge gap or difficulty faced by engineers in the shop floor (subject experts) in learning and implementing machine learning [2]. To this end, automated machine learning pipelines will help in resolving many tedious tasks. Though many AutoML pipelines are available, most of them lack good intuitive user interfaces or methods that can be implemented in an edge device, which needs models to satisfy constraints of latency and size [3].
To solve this problem, we have built an application using a web app which has an intuitive user interface with automated machine learning features that can be used to customize models for edge devices.
Objective
- Build an automated machine learning pipeline with a GUI which can be used to develop models which can be deployed on edge devices.
Methodology
To achieve the objective of finding an intuitive user interface and implementing automated machine learning and a search engine for finding the right models that can be implemented in an edge device, we conducted an extensive literature review [4][5].
We shortlisted some of the methods and tools that can be used for the implementation [6][7]. We tested some of them and concluded to use the following:
Purpose & Tools
| Purpose | Tool | Reason |
|---|---|---|
| For network training | PyTorch | Better performance for using CUDA compared to TensorFlow |
| For building UI | Streamlit | API developed in Python makes easier implementation |
| For neural architecture search engine | OFA | Compared to other NAS methods it gives lower carbon footprint |
| Deployment testing | RPi 4 | Specification of RPi is in comparison with most industrial edge devices |
| Model analysis | Sklearn | It contains ample collection of tools for model analysis |
We built a sample automated pipeline for neural network training and tested for accuracy and deployment. Once the pipeline was designed, we decomposed it into smaller functions and built a library autotorchml, and used the decomposed functions to build a user interface.
To that, we integrated the OFA neural architecture search algorithm. For testing and validation of the pipeline, we selected 2 different types of tasks which are common in smart manufacturing as benchmark tasks [8]:
- Classification
- Quality control or anomaly detection
Data Collection
For testing the application, we selected 2 different types of tasks common in smart manufacturing:
- Object classification: Hand gesture recognition dataset (6 classes)
- Anomaly detection: Tire quality control dataset (2 classes - good and defective)
Model Development
Model development can be done using the web app which we have developed. The web app currently provides two options to the user:
- Select a pre-trained model from the drop-down menu
- Curve out a custom neural architecture using Neural Architecture Search (OFA)
Neural Architecture Search
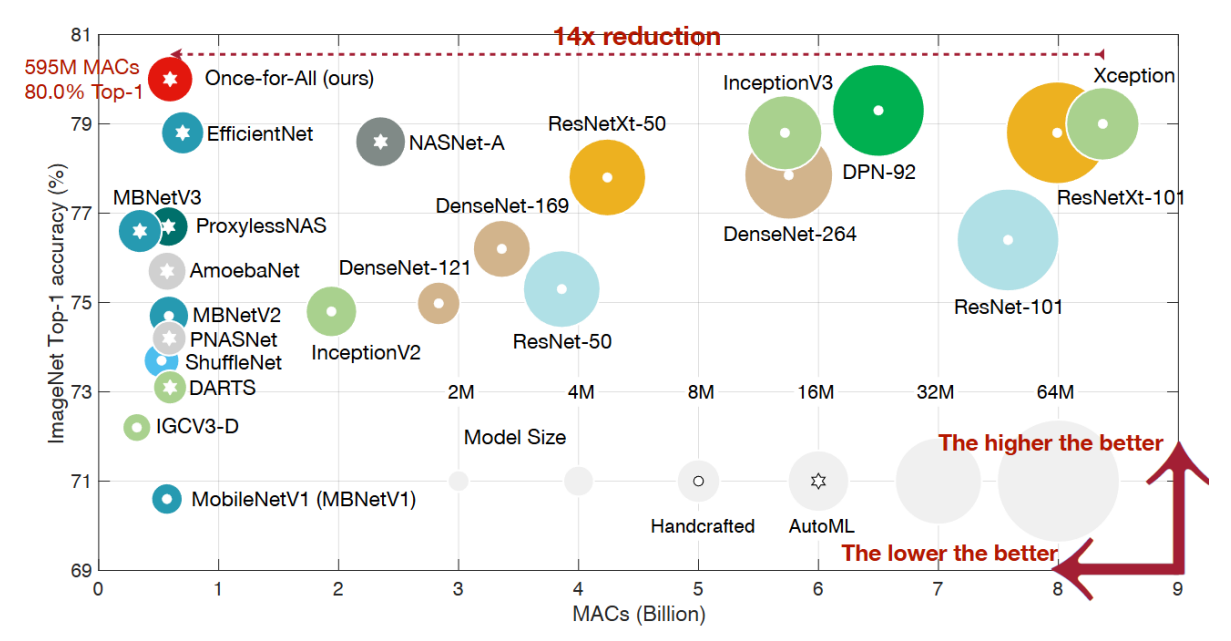
The One For All (OFA) framework is a form of Neural Architecture Search (NAS). More specifically, OFA belongs to the category of one-shot NAS methods, which aim to streamline the NAS process by training a single, large “supernetwork” capable of representing and evaluating a multitude of sub-architectures [9].
This approach leverages the principle of weight sharing, enabling efficient performance estimation without the need for training each architecture individually.
Key Differences from Traditional NAS:
- Traditional NAS: Search from scratch for each scenario (computationally expensive)
- OFA: Trains one supernetwork that supports a range of configurations (depth, width, kernel size, input resolution)
Advantages of OFA:
- “Train once, specialize many” approach
- Substantial reduction in training cost
- Fast specialization for various hardware platforms
- Optimized for resource-constrained edge devices
- Uses progressive shrinking algorithm
Testing and Results
Testing results for the 2 benchmark tasks are as follows. All 3 models were trained for 5 epochs under the following constraints:
- Latency: 20 ms
- Model Size: 20 MB
Challenges and Workarounds
- Integration of neural architecture search engine OFA in PyTorch
- Implementation of threading for running GUI and neural network training in parallel
- Design of data loaders to support various dataset formats
References
- O’Leary, Christian, Farshad Ghassemi Toosi, and Conor Lynch. “A Review of AutoML Software Tools for Time Series Forecasting and Anomaly Detection.” ICAART (3) (2023): 421-433.
- Salehin, Imrus, et al. “AutoML: A systematic review on automated machine learning with neural architecture search.” Journal of Information and Intelligence 2.1 (2024): 52-81.
- Banbury, Colby R., et al. “Benchmarking tinyml systems: Challenges and direction.” arXiv preprint arXiv:2003.04821 (2020).
- Barbudo, Rafael, Sebastián Ventura, and José Raúl Romero. “Eight years of AutoML: categorisation, review and trends.” Knowledge and Information Systems 65.12 (2023): 5097-5149.
- Rozemberczki, Benedek, et al. “Pytorch geometric temporal: Spatiotemporal signal processing with neural machine learning models.” Proceedings of the 30th ACM international conference on information & knowledge management. 2021.
- Alsharef, Ahmad, Karan Kumar, and Celestine Iwendi. “Time series data modeling using advanced machine learning and AutoML.” Sustainability 14.22 (2022): 15292.
- Truong, Anh, et al. “Towards automated machine learning: Evaluation and comparison of AutoML approaches and tools.” 2019 IEEE 31st international conference on tools with artificial intelligence (ICTAI). IEEE, 2019.
- Banbury, Colby, et al. “Micronets: Neural network architectures for deploying tinyml applications on commodity microcontrollers.” Proceedings of machine learning and systems 3 (2021): 517-532.
- Cai, Han, Ligeng Zhu, and Song Han. “Proxylessnas: Direct neural architecture search on target task and hardware.” arXiv preprint arXiv:1812.00332 (2018).
- Weng, Yu, Zehua Chen, and Tianbao Zhou. “Improved differentiable neural architecture search for single image super-resolution.” Peer-to-Peer Networking and Applications 14.3 (2021): 1806-1815.
- Cai, Han, et al. “AutoML for architecting efficient and specialized neural networks.” IEEE Micro 40.1 (2019): 75-82.
- Cai, Han, et al. “Once-for-all: Train one network and specialize it for efficient deployment.” arXiv preprint arXiv:1908.09791 (2019).