Bird Voice Recognition using Deep Learning
Introduction
This project aims to develop a deep learning–based audio classification system capable of identifying bird species through their vocalizations. In the absence of bird calls, the system classifies the input as background noise, which was explicitly included in the training dataset to improve robustness. The project was carried out in the following phases:
- Data Collection and Preprocessing: Acquired and augmented bird call and background noise datasets, followed by feature extraction using MFCC.
- Model Development: Designed and trained a lightweight Convolutional Neural Network (CNN) optimized for embedded deployment.
- Edge Deployment: Deployed the trained model on the Arduino Nano 33 BLE Sense microcontroller, enabling real-time, offline inference without internet dependency.
- Web Interface Integration: Designed a web-based interface to remotely monitor classification results using Wi-Fi-enabled communication.
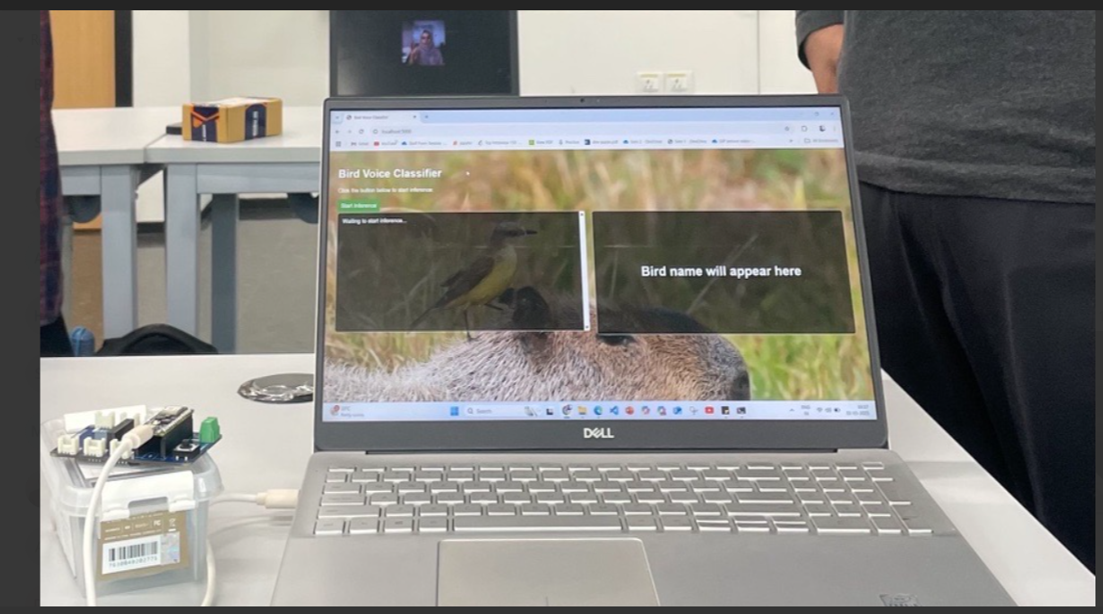
Accurate identification of bird species through their vocalizations is vital for ecological monitoring, biodiversity assessment, and conservation research. Traditionally, this process relies on manual listening and annotation, which is time-consuming, error-prone, and infeasible at scale—especially in remote or resource-limited environments.
With recent advances in embedded machine learning and edge AI, it is now possible to perform real-time classification directly on microcontrollers. This project leverages these technologies to develop a lightweight, on-device bird sound recognition system. By enabling low-cost, portable, and offline acoustic monitoring, our solution aims to support scalable and autonomous biodiversity tracking in natural and urban habitats.
Methodology
The development of the bird sound classification system involved the following key steps:
-
Data Collection and Preprocessing:
Curated a dataset comprising bird vocalizations and background noise. Audio samples were processed using Mel-Frequency Cepstral Coefficients (MFCC) to extract meaningful time-frequency features. -
Model Development:
Designed and trained a lightweight Convolutional Neural Network (CNN) using TensorFlow, specifically tailored for embedded deployment on microcontrollers. -
Model Optimization:
Applied post-training quantization to reduce memory footprint and ensure compatibility with constrained hardware environments. -
Deployment Preparation:
Converted the quantized model into TensorFlow Lite (.tflite) format and packaged it using Edge Impulse deployment tools. This generated platform-specific binaries, including a Windows batch file, for streamlined flashing onto the target device. -
Edge Deployment and Testing:
Flashed the model onto the Arduino Nano 33 BLE Sense and tested its performance with live audio input, enabling real-time classification directly on the device. -
Web Interface Development:
Built a local web interface using the Flask framework to display classification results in real time. This interface allows users to monitor bird detections over Wi-Fi within the local network, enhancing accessibility and usability.
List of hardware required and their specifications
| Components | Specifications |
|---|---|
| Arduino Nano 33 BLE Sense | ARM Cortex-M4F, onboard PDM mic, BLE |
| USB Cable | - |
| PC/Laptop | For development and flashing firmware |
List of software used
- TensorFlow 2.x – Model development, training, and quantization
- Librosa – Audio preprocessing and MFCC feature extraction
- Jupyter Notebook – Model training, evaluation, and TFLite conversion
- Edge Impulse Studio – Model packaging and deployment to Arduino
- Arduino IDE – Custom firmware integration and flashing
- Edge Impulse CLI / Serial Monitor – Real-time prediction monitoring
- Flask + Flask-SocketIO + Eventlet – Web interface for live result streaming over local network
Data collection & Preparation
We sourced bird vocalization recordings from Xeno-Canto, a globally recognized repository dedicated to sharing bird sounds. Recordings corresponding to each of the selected bird species were collected and annotated. Using the Edge Impulse data collection platform, we curated a well-structured dataset comprising 2,518 labelled audio samples across four bird species (hen_cock, Parakeet, crow, asean_koel) and background noise. This dataset was then processed and prepared specifically for the bird sound recognition task.
To prepare the data for training:
- The dataset was read using pandas, and audio files were loaded using Librosa.
- Initially, FFT-based features were tested but yielded unstable results.
- The pipeline was then switched to Mel-Frequency Cepstral Coefficients (MFCC), which provided better time-frequency resolution and model performance.
- Each audio file was transformed into an MFCC feature array with shape
(13, 32, 1), suitable for input into a lightweight CNN classifier. - Optional augmentations and careful normalization were applied during preprocessing to improve generalization and model robustness.
Model development and compression
The trained CNN model was quantized using full integer quantization with a representative dataset to calibrate the activation ranges. All operations, inputs, and outputs were forced to use int8 precision, resulting in a highly compact .tflite model (~9KB) suitable for deployment on memory-constrained microcontrollers.
Model deployment
- The fully quantized
.tflitemodel (~9 KB) was uploaded to Edge Impulse Studio for deployment. - Configured with:
- Input shape:
(13, 32, 1)(corresponding to MFCC features) - Output classes: 5 (4 bird species + background noise)
- Input shape:
- Deployed using the Arduino Nano 33 BLE Sense firmware option, which generated:
- A platform-specific firmware binary (
.bin) - Flashing scripts (
flash_mac.command/flash_windows.bat)
- A platform-specific firmware binary (
- The device was flashed via USB and tested successfully using real-time audio from the onboard microphone, enabling offline, on-device inference.
- Additionally, the same model was integrated into a Flask-based local web server, using Flask-SocketIO and Eventlet to stream classification results over Wi-Fi in real time, providing a user-friendly monitoring interface.
Prototype and Demo
Once deployed, the Arduino Nano 33 BLE Sense continuously listens to environmental audio through its onboard microphone and performs real-time inference using the quantized CNN model. Classification results, including predicted class labels and confidence scores, are streamed over the serial interface at 115200 baud, which is monitored using the Arduino Serial Monitor.
To validate the system, we tested it with a variety of pre-recorded bird call samples and real-world ambient sounds. The model reliably distinguished between the target bird species and background noise, demonstrating robust edge performance even under constrained resources.
In addition to on-device inference, a Flask-based web interface was developed to visualize predictions over Wi-Fi in real time.
Project Resources
Challenges and Workarounds
-
MFCC format mismatch between Librosa and Edge Impulse firmware
→ The MFCC features extracted using Librosa initially led to shape incompatibility during deployment. This was addressed by ensuring consistency in the input dimensions—reshaping features to(13, 32, 1)to align with Edge Impulse’s expected input format. Additionally, padding and framing were adjusted to mimic the Edge Impulse MFCC extraction style. -
Initial deployment failed on Arduino Nano 33 BLE Sense
→ Early deployment attempts failed due to unsupported operations in the model (Hybrid Model). This was fixed by applying full INT8 quantization and restricting operations to those supported by TFLite Micro, ensuring compatibility with resource-constrained MCUs. -
Edge Impulse CLI error — “Failed to find sensor axis0…”
→ This issue arose from missing or misconfigured preprocessing blocks. It was resolved by setting up a proper MFCC preprocessing block in Edge Impulse Studio to simulate real-time audio input and match the model’s input expectations. -
Unstable or inaccurate real-time predictions
→ Initially used raw FFT features, which led to poor classification stability. Switched to MFCCs for better temporal and perceptual audio representation. Additionally, improved preprocessing, filtered ambient noise, and ensured clean mic sampling. Controlled audio playback and live testing helped fine-tune stability.
References
- TensorFlow Lite Micro: https://www.tensorflow.org/lite/microcontrollers
- Edge Impulse Project: https://studio.edgeimpulse.com/public/669727/live
- Arduino Nano 33 BLE Sense: https://docs.arduino.cc/hardware/nano-33-ble-sense
- Librosa Audio Processing: https://librosa.org
- MFCC Feature Extraction: https://arxiv.org/pdf/2208.13100
- Blog: https://www.hackster.io/409822/bird-sound-classifier-on-the-edge-583563#toc-building-a-dataset-4